Salesforce Einstein: Beeinflussen unsere E-Mail-Kampagnen das Kaufverhalten?
Kohortenanalyse mit Einstein Analytics
Haben unsere E-Mail-Kampagnen einen Einfluss auf das Kaufverhalten? Eine Frage, die Marketing-Teams unter den Nägeln brennt. Insbesondere, weil das ein oder andere Sales-Team gerne die Hypothese aufstellt, dass Kampagnen einen geringeren Einfluss haben, als erhofft.
Wie lässt sich eine solche Hypothese überprüfen? Und wie können wir im Marketing verschiedene Datenpunkte nutzen, um eine Messbarkeit mit Bezug zum Kaufverhalten zu schaffen? Wie können wir nachvollziehen, welchen Wert unsere Kampagnen haben?
Bei APTLY beschäftigen wir uns intensiv mit diesem Thema und möchten Ihnen hier zeigen, wie Sie Salesforce Einstein Analytics nutzen können, um eine Kohortenanalyse durchzuführen und belastbare Antworten auf die oben gestellten Fragen zu finden.
Ausgangslage und Zielbild
Unser Ziel ist es, ein Dashboard zu kreieren, das für einzelne Kampagnen die Käufe auf der Zeitachse in drei Segmente unterteilt darstellt:
- Käufe von Kontakten, die nicht Mitglied der Kampagne sind (Vergleichsgruppe)
- Käufe von Kontakten, die mindestens eine E-Mail der Kampagne erhalten haben, aber sonst nie aktiver geworden sind (z.B. kein E-Mail Open, kein Klick, keine Anmeldung, etc.)
- Käufe von Kontakten, die nach Erhalt einer E-Mail aktiv wurden (z.B. E-Mail Open, Klick, Anmeldung, etc.)
Voraussetzung dafür ist es, dass wir passende Daten zur Verfügung haben, um einen passenden Indikator (KPI) auf der Zeitachse abzutragen: Zum Beispiel gewonnene Opportunities und deren Close Date.
Auch müssen wir davon ausgehen, dass jeder Kontakt Mitglied mehrerer Kampagnen sein kann.
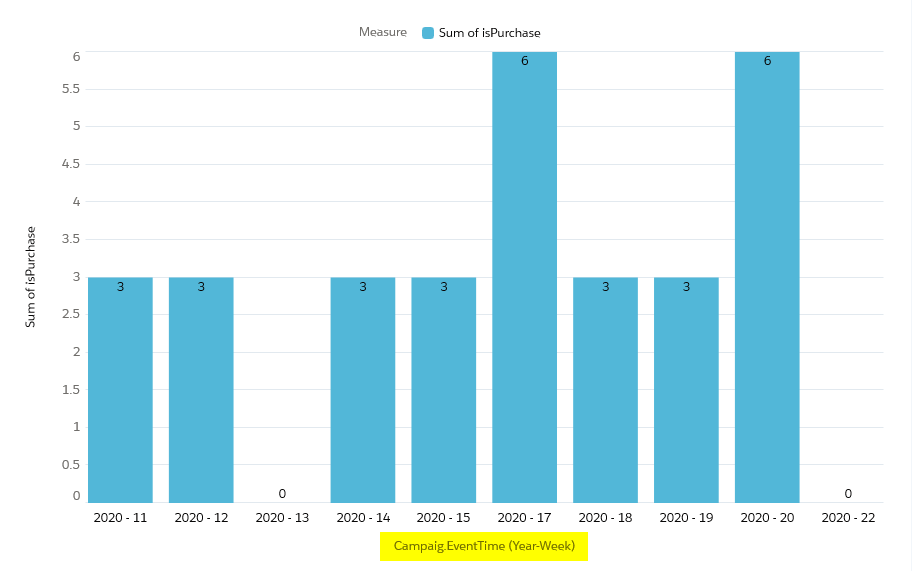
Das ganze kann dann am Ende so aussehen:
Einer solchen Darstellung können wir zum Beispiel entnehmen, dass auch Nicht-Mitglieder erwartungsgemäß Käufe abschließen. Aber Mitglieder der gewählten Kampagne, die auf die Interventionen aktiv reagieren, schließen mehr Aufträge ab.
Die Aufbereitung der Daten mit Data Flows und Recipes in Einstein Analytics
Die Grundlage für ein solches Dashboard bilden die folgenden Datentöpfe:
- Kontakte
- Kampagnen
- Campaign Member
- Und eine Zeitreihe mit Ereignissen (Close Date für Opportunities, Pardot Activity History, …)
Der Plan (theoretischer Teil)
Um die im Zielbild festgelegten Segmente darstellen zu können, müssen wir in einem ersten Schritt für alle Kampagnen den Zustand (Mitglied, nicht Mitglied) aller Kontakte ermitteln: ein kartesisches Produkt. So können wir für jede Kampagne auch auswerten, wie sich die Kontakte verhalten haben, die nicht Mitglied dieser Kampagne sind.
Angenommen, wir arbeiten mit den Kontakten A, B und den Kampagnen 1, 2 – das kartesische Produkt erzeugt daraus jede mögliche Kombination:
- A1
- A2
- B1
- B2
So können wir also jede mögliche Kombination als Kandidatenliste erzeugen. Achtung: Die Datenmengen werden schnell groß: 100 Kampagnen bei 10000 Kontakten ergeben sich 1 Million Datensätze, um alle Kandidaten abzudecken. Wie genau ein kartesisches Produkt von zwei Datasets in Einstein Analytics erzeugt werden kann, wird im praktischen Teil näher beschrieben.
Bleiben wir aber erstmal weiter bei der Theorie: Eine weitere Vorbereitung wird sein, aus der Dimension “Event Typ” eine Measure zu erzeugen, die wir in Charts leicht verwenden können, um die Häufigkeit des jeweiligen Events zu zählen.
In einem zweiten Schritt wird dieses Zwischenergebnis dann wiederum mit allen Aktivitäten eines Kontaktes angereichert. So können später die Aktivitäten im Kontext jeder Kampagnen-Kohorte betrachtet werden.
Im dritten Schritt verbinden wir Daten per Look-up mit allen Campaign Membern. Alle Kandidaten werden ergänzt um den Campaign Member Status. Und wenn es keinen gibt, wird der Kandidat dem Zustand “kein Mitglied” zugeordnet. Dazu wird ein “contactMemberKey” erzeugt, ein sogenannter Composite Key, der aus Kampagnen ID und Contact ID besteht. Beispiel: Für die Kampagne 1 und den Kontakt A soll als contactMemberKey = “1-A” verwendet werden.
Ohne Daten keine Auswertung: Unsere Testdaten
Ohne Daten geht hier nichts! Für diese Anleitung haben wir daher einige Dummy-Daten zusammengestellt. Für diese Daten wurde jeweils eine Datei in Einstein im “Create Dataset”-Prozess hochgeladen und damit ein Test Datasets angelegt.#
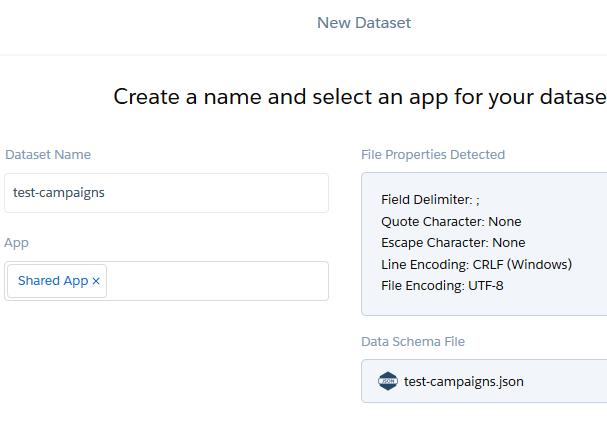
Das Ganze haben wir durchgeführt für:
- test-campaigns
- test-contacts
- test-members
- test-events
| Test Kontakte | Id;Name 003A;Contact 1 003B;Contact 2 003C;Contact 3 |
| Test Kampagnen | Id;Name 007A;Campaign A 007B;Campaign B 007C;Campaign C |
| Test Kampagnen Mitglieder | Id;ContactId;CampaignId;Status 00vA1;003A;007A;Registered 00vB2;003B;007B;Sent 00vB3;003C;007B;Participated 00vC1;003A;007C;Sent 00vC2;003B;007C;Registered 00vC3;003C;007C;Participated |
| Events | EventTime;ContactId;EventType 2020-03-21 09:00:00;003A;Sent 2020-03-21 11:00:00;003A;Click 2020-03-22 15:03:00;003A;Visit 2020-04-04 11:00:00;003A;Purchase 2020-04-08 19:00:00;003A;Click 2020-04-08 22:00:00;003A;Visit 2020-04-25 06:01:00;003A;Purchase 2020-04-14 19:00:00;003A;Purchase 2020-04-27 06:01:00;003A;Purchase 2020-05-07 06:01:00;003A;Purchase 2020-03-21 09:01:00;003B;Purchase 2020-03-21 11:01:00;003B;Visit 2020-03-30 06:01:00;003B;Visit 2020-04-28 23:01:00;003B;Click 2020-06-02 13:35:00;003B;Sent 2020-03-14 09:01:00;003C;Purchase 2020-03-18 21:17:00;003C;Click 2020-04-30 06:01:00;003C;Purchase 2020-04-05 17:48:00;003C;Sent 2020-05-13 06:01:00;003C;Purchase 2020-05-17 09:33:00;003C;Purchase 2020-06-01 03:59:00;003C;Click |
Der Data Flow
Um die gewünschten Operationen durchzuführen, müssen wir unsere Daten zunächst via Data Flows vorbereiten. Dazu wird ein neuer Data Flow erstellt: “CampaignCohort_Step1_JoinKey”.
Wie muss dieser Data Flow konkret aussehen?
Wir möchten später das kartesische Produkt in einem Recipe mit einem “Full Outer Join” erzeugen. Dazu benötigen wir aber einen Key, mit dem der Join wie gewünscht durchgeführt werden kann. Das bedeutet also: In einem ersten Schritt müssen wir diesen Key zunächst erzeugen.
Dazu bauen wir den Data Flow bestehend aus drei Knoten auf:

Der erste Knoten – “campaigns” – liest das Dataset “test-campaigns”. Dies ist ein ‚edgemart‘, um das Test Dataset einzulesen. Das kann aber z.B. auch ein sfdcDigest Knoten sein.
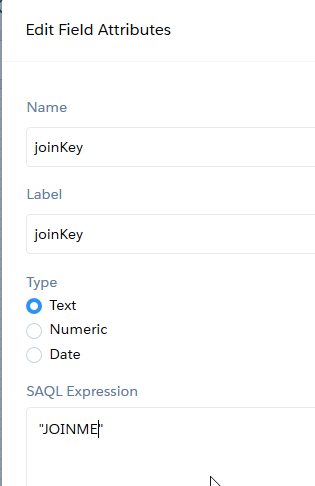
Der zweite Knoten – “campaignJoinKey” (computeExpression) – erzeugt den Join Key. Die Parameter für das Feld “joinKey” werden wir folgt eingestellt:
- Name: joinKey
- Label: joinKey
- Type: Text
- SAQL Expression: “JOINME”
Durch diese SAQL Expression wird die Dimension joinKey mit dem konstanten Wert “JOINME” einheitlich für alle Zeilen eingefügt.
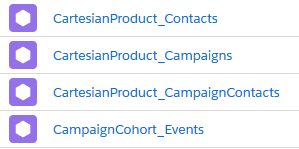
Der dritte Knoten – “outCampaigns” – ist vom Typ sfdcRegister und schreibt die Daten ins Dataset, das später wieder verwendet wird. Als Namen für das Ziel-Dataset wählen wir “CartesianProduct_Campaigns”.
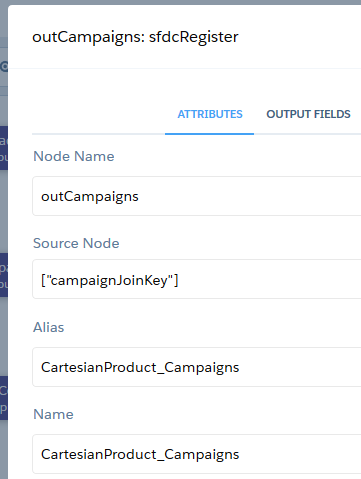
Dieses Vorgehen wiederholen wir nun für Kontakte. Den Knoten “outContacts” konfigurieren wir so, dass das Ziel-Dataset “CartesianProduct_Contacts” heißt.
Nachdem nun jeweils für Kontakte und Kampagnen drei Knoten angelegt und verbunden wurden, sieht unser Dataflow so aus:
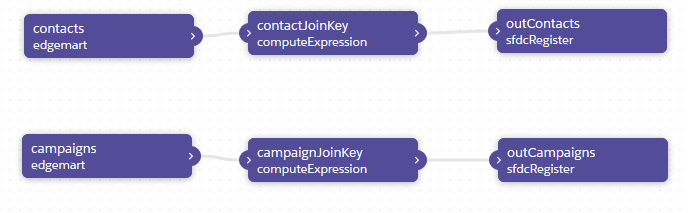
Im nächsten Schritt bleiben wir in diesem Dataflow und ergänzen Campaign Member. Um gleich die Verbindung des kartesischen Produkts mit den Campaign Member vornehmen zu können, erzeugen wir für jedes Member den “contactMemberKey”.
Das Prinzip ist dasselbe wie vorher: drei Knoten jeweils zum Einlesen, Erweitern, Ausgeben.

Der mittleren Knoten, “addContactMemberKey” (computeExpression) wird wie folgt aufgebaut:
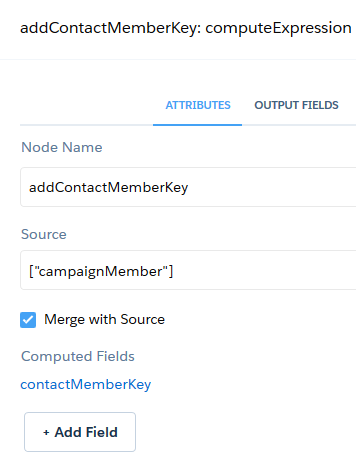
Hier wird ein berechnetes Feld “contactMemberKey” eingefügt. Dieses Feld ist ein Text-Feld, die SAQL Expression lautet:
‚CampaignId‘ + „-“ + ‚ContactId‘
(!) Achtung: Die Verwendung von Single Quotes und Double Quotes ist sehr wichtig. Single Quotes umschließen Feldbezeichnungen, Double Quotes umschließen einfachen Text.
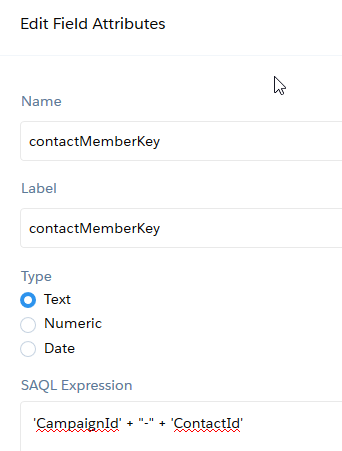
In den Parametern des Knotens “outCampaignMembers” geben wir an, dass das Ziel-Dataset “CartesianProduct_CampaignContacts” heißen soll.
Fast geschafft, nun haben wir 9 Knoten im Dataflow.
Es fehlt nur noch eine weitere Ergänzung: Wir müssen aus der “EventType” Dimension der Eventliste noch eine zählbare Measure erzeugen.
Dazu legen wir (Überraschung!) wieder drei Knoten an: Einlesen, Erweitern, Ausgeben.

Das Besondere diesmal ist der Knoten “eventClassification”. Hier erzeugen wir ein Number-Feld “isPurchase”:
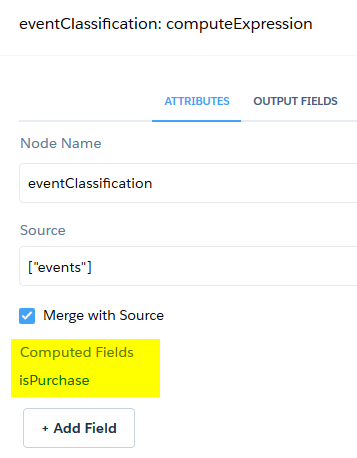
Dazu verwenden wir folgende SAQL Expression, die das Feld “isPurchase” auf 1 setzt, wenn der EventType = “Purchase” ist.
Den Parameter Precision (maximale Größe der Zahl) setzen wir auf 8 und Scale (Dezimalstellen) auf 0.
case
when 'EventType' == "Purchase" then 1
else 0
end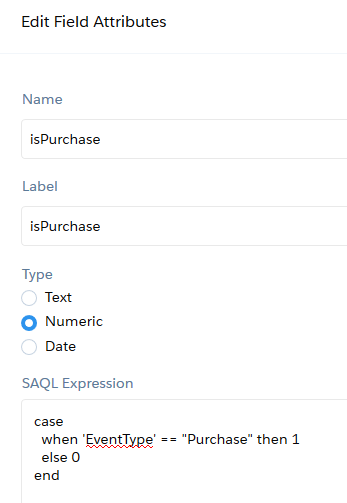
In den Parametern des Knotens “outEvents” geben wir an, dass das Ziel-Dataset “CampaignCohort_Events” heissen soll.
Geschafft. Unser Dataflow hat jetzt 12 Knoten:
- Für Kampagnen und Kontakte wird jeweils der joinKey erzeugt
- Für Kampagnenmitglieder wird der contactMemberKey erzeugt
- Und für Events wird isPurchase berechnet.
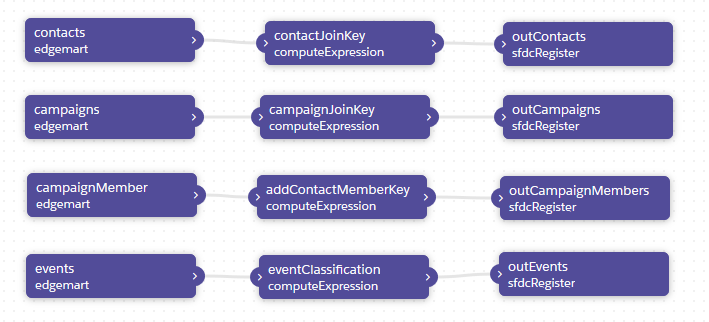
Dieser Dataflow muss gespeichert (“Update Dataflow”) und gestartet werden (“Run Dataflow”).
Im Monitoring warten wir nun darauf, dass der Flow erfolgreich abgeschlossen wird.
Der Dataflow hat nun die definierten vier Datasets erzeugt:
Die Umsetzung
Nun haben wir alle Vorbereitungen getroffen, um in die Umsetzung zu gehen.
Unsere Testdaten enthalten drei Kampagnen und drei Kontakte. Das Ergebnis dieses Schritts ist eine Liste mit neun Einträgen, die alle möglichen Kombinationen aus Kampagnen und Kontakten abdeckt. Nun legen wir das Rezept an.
Schritt 1: Das kartesische Produkt
Jetzt kanns losgehen: Wir beginnen damit, auf der Grundlage des Datasets “CartesianProduct_Campaigns” ein Rezept mit dem Namen “Campaign Cohort – Purchase Influence” anzulegen:
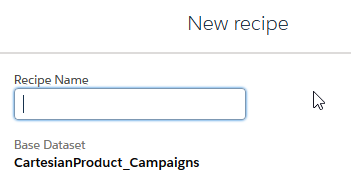
In dieses Rezept, das auf den Kampagnendaten aufbaut, fügen wir einen “Add Data”-Schritt ein. Als Datenquelle wählen wir “CartesianProduct_Contacts”, die Join Keys müssen die im Dataflow erzeugten Felder “joinKey” sein und der Typ des Join ist “Full Outer Join”:
Dieser Schritt erzeugt bereits das kartesische Produkt: Estimated Input Rows: 3, Estimated Output Rows: 9.
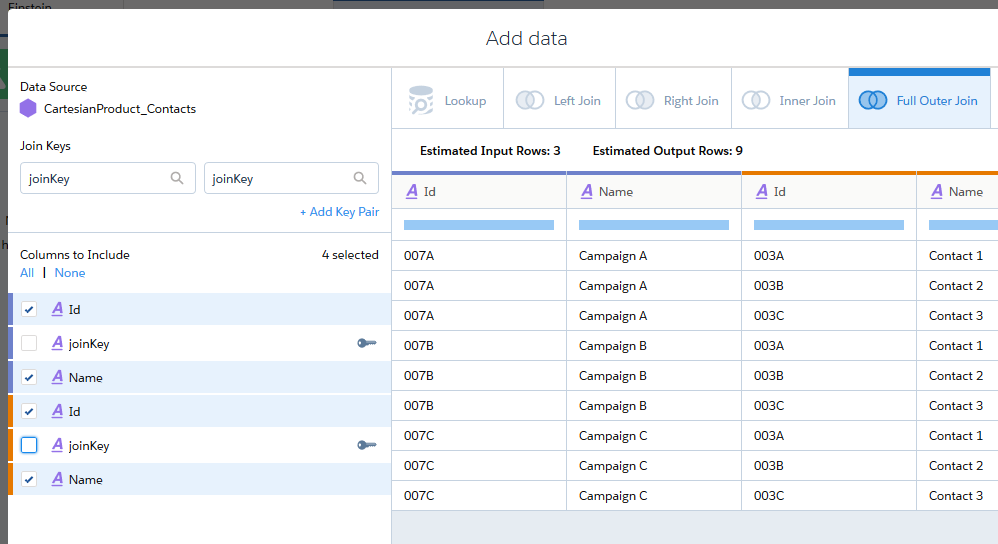
Nun speichern wir und kehren zurück zur Rezept-Übersicht.
Schritt 2: Campaign Member Daten verbinden
Die im vorherigen Schritt erzeugte Liste enthält alle denkbaren Kombination von Kontakten und Kampagnen.Nun müssen wir jede Zeile mit der Information anreichern, ob die jeweilige Kombination auch wirklich vorgekommen ist. Dazu erzeugen wir einen neuen Schlüssel, mit dem wir die Campaign Member verbinden können. Dafür wird der Composite Key, bestehend aus Campaign ID und Contact ID verwendet.
Wir suchen das Feld “CampaignId”, öffnen das Kontextmenü und wählen den Punkt “Formula” aus, um ein berechnetes Feld zu erzeugen:

Die Formel für dieses Feld lautet:
concat([Id], „-„, [Cartesi.Id])
So erzeugen wir für jede Kombination aus Kampagnen ID ([Id]) und Contact ID ([Cartesi.Id]) den Schlüssel. Für Kampagne 1 und Kontakt A wird also der contactMemberKey = “1-A” erzeugt. In den Attributen dieses Feldes ändern wir nun noch den API Namen und das Label zu “contactMemberKey”.
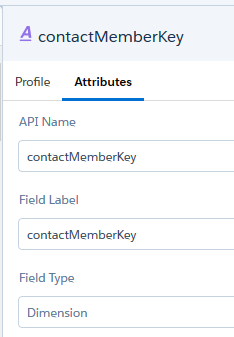
Zwischenstand: Nun haben wir zwei Rezept-Schritte erstellt:

Schritt 3: Event-Daten verbinden
Nun fügen wir mit einem weiteren “Add Data”-Schritt die Event-Daten hinzu. Die Datenquelle für diesen Schritt muss “CampaignCohort_Events” sein. Als Join Keys müssen die Contact ID aus dem kartesischen Produkt sowie die Contact ID aus den Event-Daten verwendet werden. Der Join-Typ ist erneut “Full Outer Join”.
Als Felder, die hinzugefügt werden sollen, wählen wir alle Felder aus den Event-Daten aus.

Diesen Schritt speichern wir mit “Done” ab.
Schritt 4: Anreichern des Campaign Member Status mittels contactMemberKey
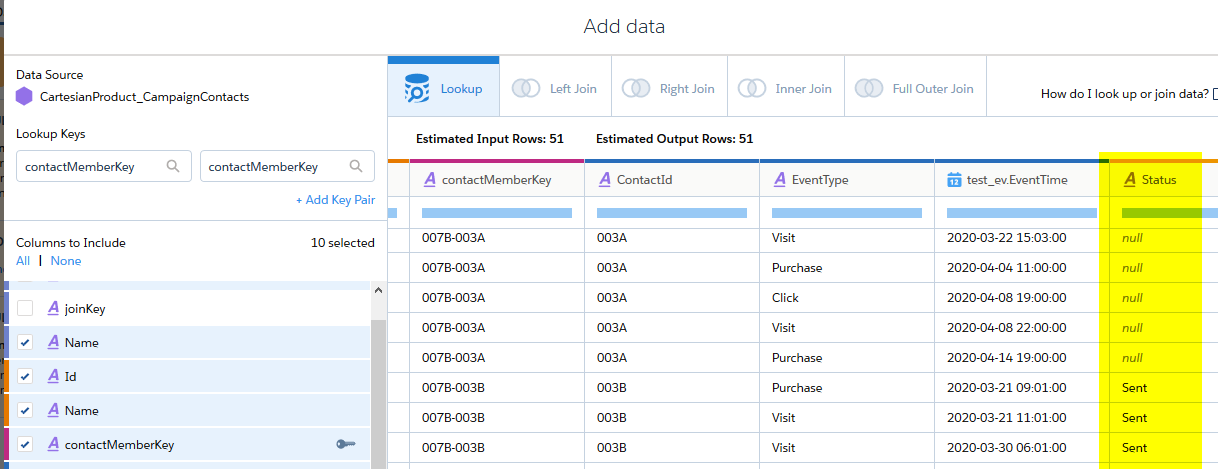
Nun müssen wir noch mit Hilfe des contactMemberKey den Campaign Member Status anreichern. Dazu muss erneut ein “Add Data”-Schritt eingefügt werden, diesmal mit der Datenquelle “CartesianProduct_CampaignContacts”.
Als Lookup Key kann auf beiden Seiten der contactMemberKey gewählt werden, der einerseits mit dem Formel-Feld im Rezept, andererseits in der Vorbereitung durch den Dataflow erzeugt wurde. Zur Erinnerung: Das ist der Composite Key, bestehend aus Campaign ID und Contact ID.
Die Art der Datenanreicherung ist ein “Lookup”.
Jetzt sind für alle Kampagnen/Kontakt-Kandidaten die Events des jeweiligen Kontakts angereichert und im Kontext der Kampagne um den Status des Kontakts in der Kampagne ergänzt: Wenn der Status “null” ist, ist der Kontakt kein Mitglied der Kampagne.
Schritt 5 und 6: Null-Werte ersetzen und drei Klassifizierungen aufbauen
Wir möchten auf dem Dashboard explizit drei Werte sehen:
- 01 – no Member
- 02 – Sent // wenn der Status des Mitglieds “Sent” ist
- 03 – Reacted // wenn das Mitglied aktiv reagiert hat. Der Status wird Participated oder Registered sein.
Um später auf den Dashboards die gewünschte Sortierung zu erhalten, können wir die Ziffern 01, 02, 03 den Werten voran stellen.
Zunächst ersetzen wir nun den “null”-Wert im Status Feld: Für das Status-Feld muss die Replace-Operation angewendet werden: Search for null replace with “no Member”.
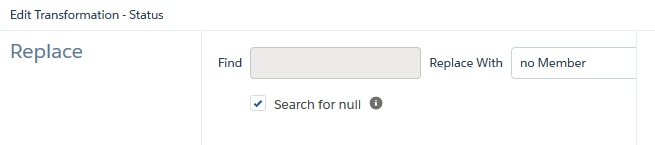
Diese Replace-Operation erzeugt ein neues Feld, dass wir “cohortStatus” / “Cohort Member Status” nennen. Aus diesem Feld muss als nächstes ein Bucket-Feld erstellt werden. Der Bucket mit dem von uns gewählten Namen “01-no Member” ergibt sich aus “Bucket remaining values”.

Kontrollpunkt: Es muss jetzt 6 Schritte in diesem Rezept geben:
- Full Outer Join von Kampagnen und Kontakten, um das kartesische Produkt zu erzeugen
- Formel-Feld zur Berechnung des contactMemberKey
- Full Outer Join um die Event-Daten anzureichern
- Lookup, um Kampagnen-Mitgliedsstatus mittels contactMemberKey einzufügen
- Replace, um null-Werte zu ersetzen
- Bucket, um verschiedene Status zu gruppieren und drei Klassifizierungen zu erhalten

Das Rezept anwenden und das Ziel-Dataset erzeugen
Jetzt nicht schlapp machen! Der Dialog über “Update Dataset” führt uns zum Abschluss: Das zu erzeugende Dataset nennen wir “CampaignCohort_CampaignContacts”, und speichern es in die “Shared App”.
Bei der Auswahl der Felder ist darauf zu achten, Redundanzen zu vermeiden.

Das Ergebnis
Das Dataset CampaignCohort_CampaignContacts kann nun verwendet werden, um die Measure “isPurchase” im Kontext einer gewählten Kampagne zu betrachten.
Achtung: Durch den Aufbau dieser Daten und die mehrfach (für jedes Kampagne/Kontakt-Paar) eingefügten Event-Daten ist die Interpretation der Daten nur sinnvoll für jeweils eine Kampagne. Ohne einen gesetzten Filter auf eine Kampagne ergeben sich für die Gesamtdaten sonst zwangsläufig falsche Summen.
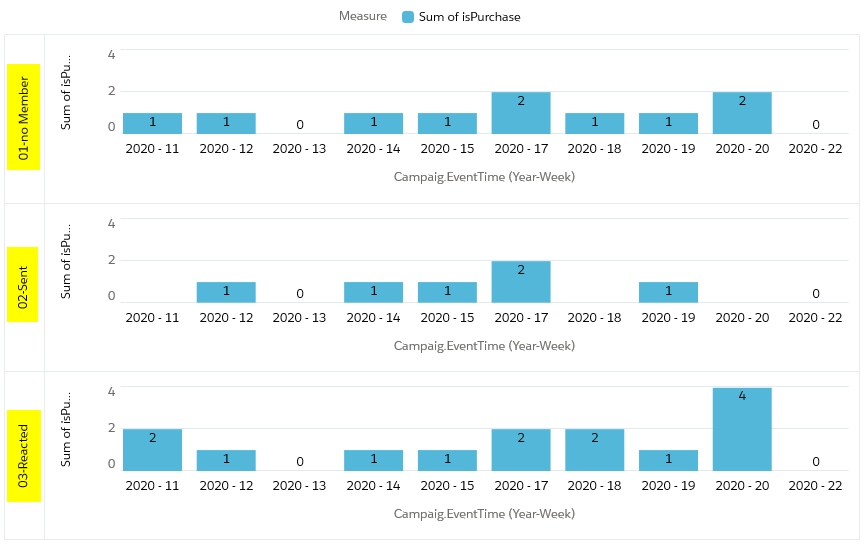
Auf dem Dashboard sieht das ganze nun so aus:
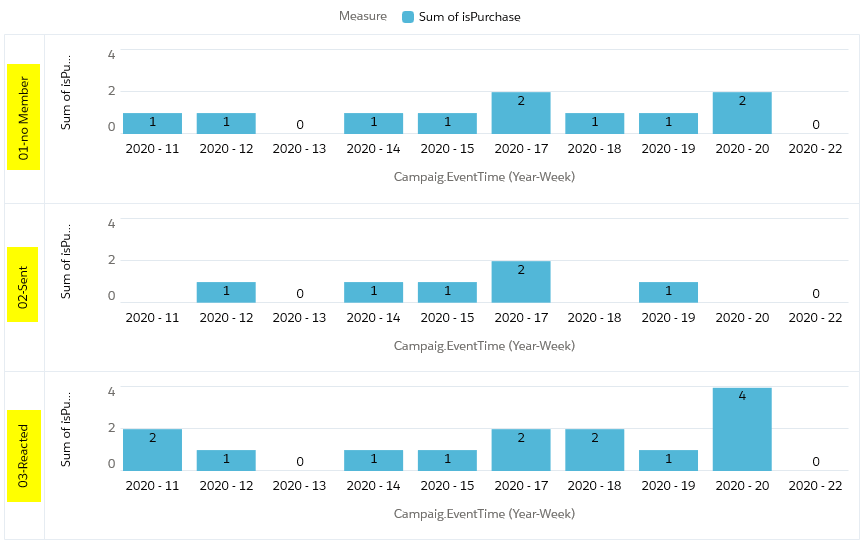
Die Darstellung kann je nach Präferenz und Fokus individuell angepasst werden, hier eine alternative Darstellung der gleichen Daten:
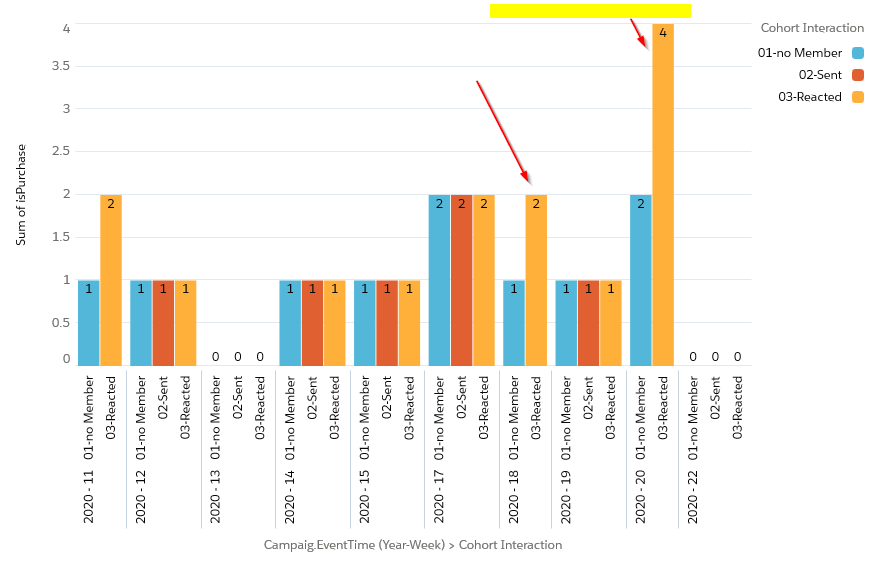
Zugegeben, diese Umsetzung ist nicht straight-forward und durch die Verwendung von Dataflows und Rezepten, die aufeinander aufbauen, kann es schnell unübersichtlich werden.
Mit dem Sommer 20 Release wird das neue Data Prep 3.0 in die public beta Phase gehen. Wir erwarte derzeit, dass damit einiges der hier auf Dataflows und Rezepte verteilten Schritte mit einem neuen Data Prep Editor erstellt werden kann.
Bei Fragen rund um die Datenanalyse mit Einstein Analytics oder zu dieser Anleitung im speziellen stehen wir Ihnen jederzeit zur Seite. Wir freuen uns auch über einen Austausch: Nutzen Sie Einstein Analytics bereits, um Kampagnenerfolge zu messen? Wir sind gespannt auf Ihre Ansätze!